

AI
AI Jira Sprint summaries: save hours on reporting
Automate Jira sprint reporting: get real-time insights, detect risks, and eliminate manual updates. Save time & keep teams aligned effortlessly.



.svg)

How we built a contextual RAG to understand meeting notes and Slack. Here's our step-by-step guide.

At Luna AI, we’ve been building AI features like automated sprint summaries, mostly powered by structured Jira data and some unstructured content like comments and ticket descriptions.
But here’s the truth:
→ Most product decisions don’t live in Jira. They live in chaotic meeting notes and Slack threads.
These sources capture the real-time “why” behind product work: the tradeoffs, blockers, risks, and decisions that never make it into Jira fields. But they are messy: long, inconsistent, and unstructured.
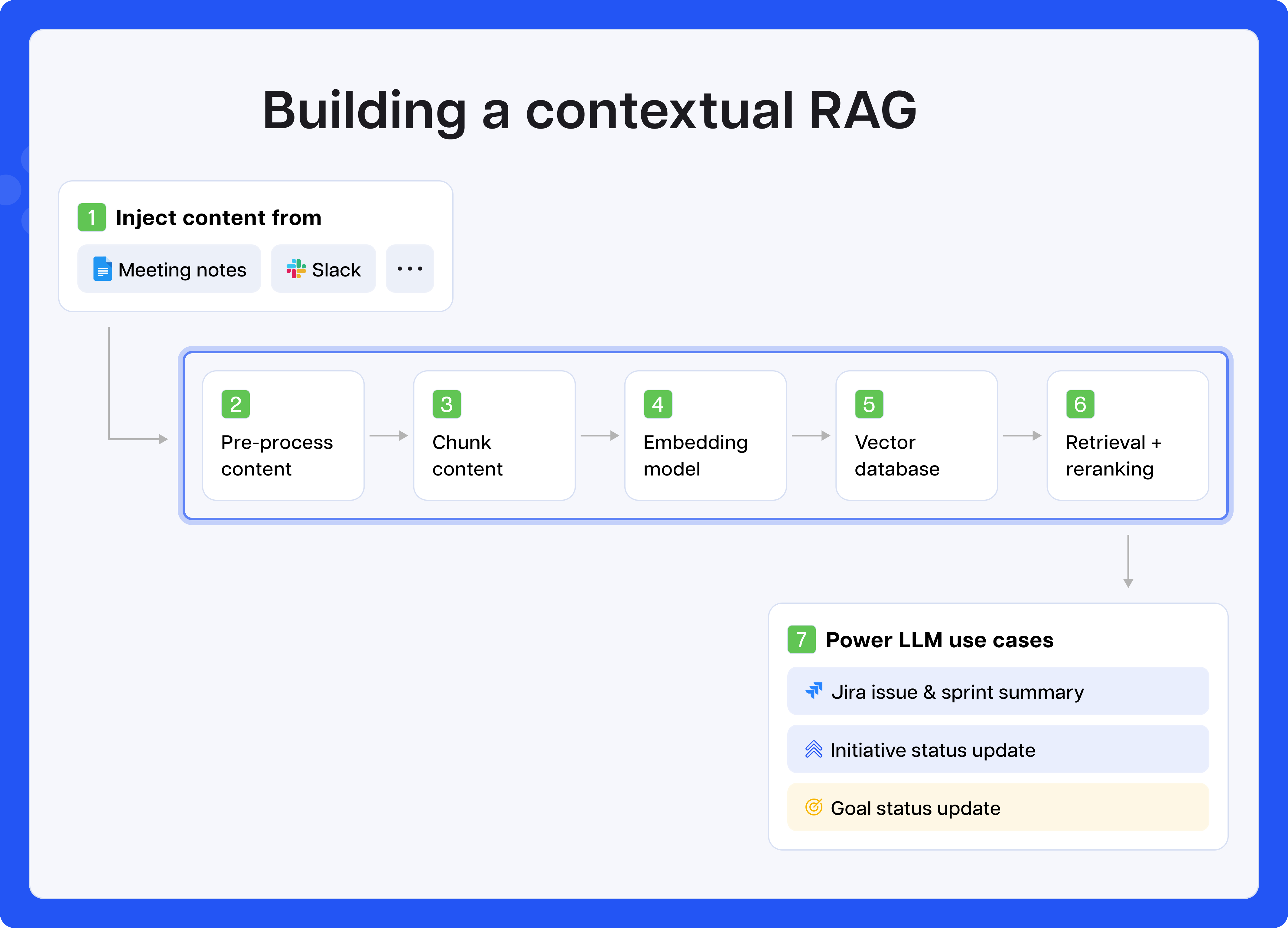
To make sense of this chaos, we built a simple contextual RAG pipeline designed specifically for product teams. Unlike generic RAG approaches that treat all text equally, ours understands:
This post walks through our implementation, from the initial chunking challenges to the contextual metadata that now powers our contextual RAG and AI use cases.
Meeting notes contain the DNA of product decisions, but they're structured like stream-of-consciousness rather than databases. A typical 30-minute standup note might cover:
Here’s a real excerpt from our Sports Launch meeting:
“Launch timeline confirmed for March 15th. Authentication team reports 2-week delay due to iOS regression affecting login flow. Alex flagged in #ios-eng that crash rate jumped to 3.2% on 16.2 devices. Decision: we're pushing auth to v2, launching with guest mode only. Sarah will update roadmap. Discussed A/B test results showing 12% conversion lift with new onboarding flow.”
Now imagine asking your AI system
“What are the key risks for Sports Launch?”
A standard RAG system might:
You’re left guessing:
Popular guides about simple RAGs on HuggingFace or Mistral focus on mechanics like:
But that falls apart when your data looks like:
The core problems with naive RAG:
→ Anthropic’s recent post on Contextual Retrieval makes this point clearly: useful retrieval depends on structured, contextual metadata.
To fix this, we built our own contextual RAG pipeline, tailored to how product and engineering teams actually communicate.
Every sentence in a meeting note or Slack message is:
launch_titles, jira_ids, sprint_ids, users, etc.This connects unstructured text to your structured company data.risk, decision, status, dependency, etc.This approach ensures that we retrieve precise, structured, and relevant context, so downstream LLMs don’t get confused or hallucinate. It also keeps prompts small and sharp.
We chose this structured approach to retrieval for three key reasons:
The following are high level steps to implement a contextual RAG. Of course, these are the “foundations”, which you should make your own and build on. The goal is to optimise for output:
Instead of naive chunking by character count, we use an LLM to break notes and Slack messages into semantically meaningful segments.
Each segment is enriched with:
Example segment:
{
"text": "iOS regression from auth team is delaying rollout",
"segment_index": 3,
"anchor": "Launch: Sports Expansion",
"label": "risk",
"source": "weekly_meeting_notes_2025_07_01",
"timestamp": "2025-07-01"
}
This turns messy paragraphs into structured building blocks that are searchable, filterable, and semantically tagged.
Next, we group semantically related segments by anchor. This lets us build tight, topic-specific chunks for retrieval:
We keep chunks under ~300–500 tokens to ensure compact, relevant prompts for downstream LLMs. You can implement a dynamic token limit and use a re-ranker that will only prioritise high precision chunks.
→ Why this matters:
Instead of dumping entire documents into the context window, we pass only what’s relevant to the query’s intent and topic.
We store these structured chunks in a vector database (e.g., Weaviate, Qdrant, or Postgres + pgvector), along with rich metadata for filtering.
Each chunk includes:
launch_id, jira_id, etc.risk, decision, etc.This lets us do both semantic search (via embeddings) and precise filtering (via metadata).
When a user asks a question (e.g. “What are the top risks for Launch B?”), we:
anchor = Launch B)label = risk)This produces focused, high-quality summaries, instead of generic or hallucinated responses.
Another design principle: we distinguish between short-term memory and long-term memory, a critical step for turning noisy inputs into a reliable source of truth.
To bridge the gap between unstructured insight and structured reality, we run equivalence checks during preprocessing:
This grounding ensures we don’t treat vague, ambiguous references as truth and lets us build a consistent product graph that ties everything together.
.png)
Anthropic’s approach (see their blog) retrieves entire documents and injects them into Claude’s 200K-token context window.
Where it shines:
Where we differ:
Product and engineering teams don’t need another AI tool that just summarizes random text. They need a system that understands the structure of their work, and reflects how teams actually operate.
By grounding unstructured inputs (like meeting notes and Slack) in structured context (like launches, epics, and risks), our contextual RAG unlocks powerful use cases.
You can now ask:
“What are the top 3 risks flagged across launches in the last 2 weeks?”
And instead of guessing, the system will:
Contextual RAG isn’t just a technical pattern, it’s a foundation for something much bigger:
This is how we move beyond chatbots and into real operational intelligence: AI that helps teams work faster, align better, and ship smarter.
.svg)




.png)



